2.1 Marqueur prédictif (modificateur d’effet)
4 L’évaluation des marqueurs prédictifs
5 La personnalisation sur le risque de base
7 L’évaluation de l’utilité clinique par les essais de stratégie
Le concept de marqueur/facteur prédictif désigne un facteur associé avec une modification de l’effet du traitement [33 , 34 , 35] . En d’autres termes, avec un marqueur prédictif binaire (présent/absent, positif/négatif) l’effet du traitement n’est pas le même chez les patients présentant le marqueur (dits patients marqueurs positifs) et chez les patients ne le présentant pas (dits patients marqueurs négatifs).
Rien n’interdit que le marqueur prédictif soit de nature continue, modulant progressivement l’effet du traitement. En pratique ces marqueurs sont souvent binarisés pour gagner en simplicité d’utilisation même si cela entraine une perte d’information.
Le marqueur prédictif idéal serait un marqueur qui permettrait d’identifier les patients chez lesquels le traitement serait sans effet (patients répondeurs/non répondeurs).
Il est souvent fait référence aux facteurs de « réponse au traitement ». Même si cette appellation pourrait être comprise comme marqueurs prédictifs, elle fait référence à une approche différente et inappropriée qui est celle du pronostic sous traitement (cf. section 4.1). Cette approche ne permet pas d’identifier des marqueurs prédictifs, car elle ne repose pas sur les effets traitements, mais simplement sur le risque (cf. section 2.2).
La détermination de l’effet du traitement demande une comparaison entre un groupe traité et un groupe contrôle. Le concept de marqueur prédictif recouvre ainsi deux niveaux de comparaison reposant sur 4 groupes de patients.
Classiquement, l’effet du traitement se mesure par un hazard ratio, un risque ratio (risque relatif), un odds ratio, une différence de moyenne, etc. note n° 5 . Avec le risque ratio, par exemple, le concept de marqueur prédictif signifie que le risque ratio du traitement considéré par rapport à son contrôle n’est pas numériquement identique entre les patients marqueurs positifs et ceux marqueurs négatifs. Schématiquement, cela se matérialise numériquement de la façon suivante :
Patients |
Décès de toute cause Risque ratio |
Marqueurs positifs |
0.8 |
Marqueurs négatifs |
1.0 |
Dans cet exemple, le traitement entraine une réduction relative du risque de -20% chez les patients présentant le marqueur (marqueur positif) tandis qu’il ne semble pas apporter de bénéfice de survie chez les patients marqués négatifs. Bien entendu, l’analyse formelle de ces résultats nécessite de prendre en considération l’incertitude statistique des estimations (cf. infra).
Comme le risque ratio est issu de la comparaison d’un groupe traité et d’un groupe contrôle, le tableau complet comprend 2 colonnes supplémentaires :
Décès de toute cause nombre (%) |
|||
Patients |
Risque ratio |
Groupe traité n=1000 |
Groupe contrôle n=1000 |
Marqueurs positifs |
0.8 |
64/400 (16%) |
80/400 (20%) |
Marqueurs négatifs |
1.0 |
120/600 (20%) |
120/600 (20%) |
Les données sources sont celles des 4 groupes qui apparaissent ainsi (marqueur positif, traité ; marqueurs positifs, contrôle ; marqueur négatif, traité ; marqueurs négatifs, contrôle). Pour mémoire, le risque ratio de 0.8 est obtenu par la division de 16% par 20%.
Il apparait ainsi que le concept de marqueur prédictif s’apparente tout simplement aux analyses en sous-groupes des essais thérapeutiques. Toutes les variables utilisées pour faire des analyses en sous-groupes permettent d’explorer si celles-ci modifient l’effet du traitement et pourraient donc avoir une valeur prédictive. Néanmoins la démonstration de la valeur prédictive d’une variable va aller bien au-delà d’une simple analyse en sous-groupe compte tenu de toutes leurs limites méthodologiques (cf. Dossier 5 – Les analyses en sous-groupes ).
En cas de marqueur n’ayant pas de valeur prédictive, un risque ratio similaire serait observé chez les 2 types de patients, comme dans cet exemple :
Décès de toute cause nombre (%) |
|||
Patients |
Risque ratio |
Groupe traité n=1000 |
Groupe contrôle n=1000 |
Marqueurs positifs |
0.7 |
56/400 (14%) |
80/400 (20%) |
Marqueurs négatifs |
0.7 |
90/600 (15%) |
120/600 (20%) |
La simple comparaison des effets traitements (estimation ponctuelle) n’est cependant pas suffisante pour conclure à une modification d’effet. Il est nécessaire de prendre en compte l’incertitude statistique de ces deux estimations. En effet, il est nécessaire d’exclure la possibilité que les 2 effets traitements observés ne soient différents que du fait du hasard. Il est donc nécessaire de montrer que la différence d’effet observée entre les marqueurs positifs et les marqueurs négatifs est statistiquement significative, c’est-à-dire qu’elle est bien réelle compte tenu de l’incertitude qui entache chaque estimation.
Intuitivement, il est possible de percevoir que, si les intervalles de confiances des effets traitements se chevauchent largement, il n’est pas possible d’affirmer que les effets sont réellement différents, car, par exemple, la valeur obtenue avec les marqueurs positifs est alors compatible avec les valeurs d’effet possible pour les marqueurs négatifs compte tenu de l’incertitude de l’estimation chez ces derniers patients, et vice versa.
Ce raisonnement graphique, même s’il permet d’intuiter la problématique, n’est que partiellement exact. L’approche formelle de la question « l’effet du traitement est-il statistiquement différent entre les marqueurs positifs et les négatifs » se fait à travers la notion de test d’interaction. Ce test donne une p value de comparaison des effets. Lorsque cette p value est inférieure au seuil de la signification statistique (5% le plus souvent, mais d’autres valeurs sont parfois rencontrées pour ce test d’interaction) il est alors possible de conclure à une modification de l’effet par le marqueur considéré. Si le test d’interaction est non significatif, il est alors hasardeux de conclure à une différence d’effet comme à une absence de différence (compte tenu de la faible puissance des tests d’interaction le plus souvent [36] ).
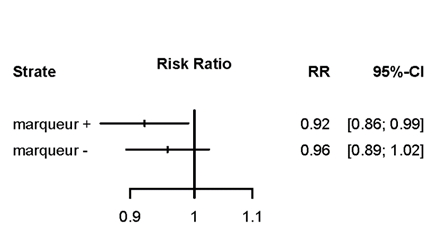
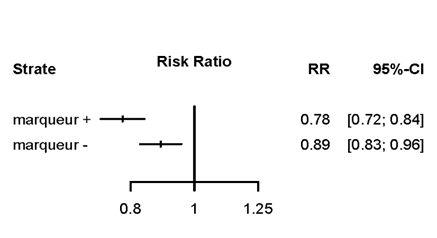
La figure ci-dessous illustre l’utilisation du test d’interaction. Dans la sous-figure de gauche, le test d’interaction n’est pas statistiquement significatif et ne permet pas de conclure qu’il y a une différence de l’effet entre les marqueurs positifs et les marqueurs négatif (en d’autres termes, compte tenu de leur incertitude respective, le risque ratio de 0.92 ne peut pas être considéré comme différent de 0.96). Dans la sous-figure de droite, le test d’interaction
p interaction = 0.45 |
p interaction = 0.01 |
Ce test d’interaction permet de montrer qu’il existe une interaction entre l’effet du traitement et le marqueur sur la fréquence du critère de jugement (appelé le risque en épidémiologie), ce terme interaction signifiant que l’effet du traitement varie en fonction des modalités du marqueur considéré.
La Figure 2 ci-dessous donne une illustration de cette notion d’interaction. L’ordonnée représente le risque (la fréquence du critère de jugement). Les risques observés dans les quatre groupes (cf. supra) sont positionnés sur cette échelle (les points). Les deux strates de patients définies par le marqueur figurent en abscisse. Dans la strate des patients marqueurs positifs (à droite) le traitement à un effet sur le risque du critère de jugement (le risque est plus faible avec le traitement qu’avec le placebo). Cet effet du traitement peut être quantifié par le risque ratio qui est de 0.4 (rapport des risques, traitement versus placebo). Pour la strate des patients marqueurs négatifs, le traitement a aussi un effet sur le risque puisque celui-ci est, aussi chez ces patients, plus faibles sous traitement que dans le groupe placebo. Cet effet du traitement est caractérisé par un risque ratio de 0.8. Cependant le marqueur n’a pas d’effet sur le risque comme en témoigne la même valeur de risque observé dans le groupe placebo entre les marqueurs positifs et les marqueurs négatifs (il n’est donc pas pronostique). Ainsi la différence de risque chez les patients traités entre les marqueurs positifs et les marqueurs négatifs n’est pas le reflet d’un effet pronostique note n° 6 du marqueur sur le risque lui-même, mais d’une modification par le marqueur de l’effet du traitement, le marqueur interagit sur l’effet du traitement sur le risque.
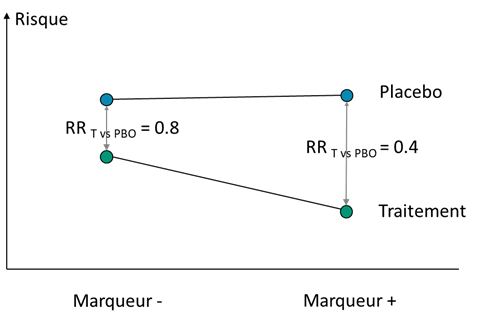
Figure 2 – illustrations du concept d’interaction
L’identification d’un marqueur prédictif nécessite donc la mise en évidence d’une interaction statistiquement significative entre l’effet du traitement et le marqueur. Mais cette condition n’est pas suffisante. Il faut aussi qu’elle témoigne d’une disparition de l’effet du traitement dans une des deux strates
[5] Cf. dossier indices d’efficacités et analyse des courbes de survie
[6] Cf. section suivante 2.2