4 L’évaluation des marqueurs prédictifs
5 La personnalisation sur le risque de base
5.1 Variation du bénéfice absolu en fonction du risque de base
5.2 Mise en application pour personnaliser les traitements
5.3 Évaluation clinique d’une personnalisation sur le risque
5.3.1 Performance d’un outil de prédiction
5.4 L’évaluation de l’utilité clinique
7 L’évaluation de l’utilité clinique par les essais de stratégie
Une bonne performance de l’outil prédictif n’est pas une preuve suffisante, mais représente néanmoins un prérequis. La description en détail de la méthodologie d’évaluation de la performance des outils prédictive dépasse le cadre de document. Nous ne présenterons ici que les bases nécessaires à une bonne compréhension de l’évaluation de l’utilité clinique de la personnalisation sur le risque de base. Pour plus de détails, le lecteur pourra consulter les nombreux ouvrages et publications consacrées à cette thématique [87 , 88] .
La performance prédictive dépend de 2 dimensions : la capacité de discrimination et la calibration [89] .
La discrimination est l’aptitude de l’outil à distinguer les patients en fonction de leur risque, c’est-à-dire à prédire une plus forte probabilité pour les patients qui font un évènement que ceux qui ne le font pas. Il existe plusieurs possibilités de mesurer cette capacité comme la courbe ROC avec la surface sous la courbe et la statistique C [90] . Une valeur de C de 0.5 marque l’absence totale de valeur prédictive tandis que la valeur 1 signifie une capacité parfaite à séparer les patients en fonction de la survenue ou non de l’évènement.
Cette courbe ROC est tracée en faisant varier un seuil de risque prédit. Pour chaque valeur de seuil, la sensibilité de la discrimination effectuée par ce seuil est la proportion de patients avec évènement au-dessus de ce seuil et la spécificité est la proportion de patients sans évènement en dessous du seuil.
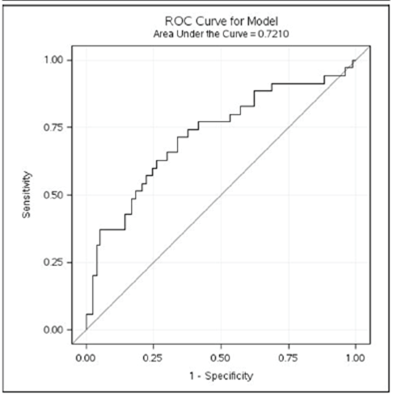
La capacité de discrimination n’est pas suffisante à elle seule pour évaluer la performance prédictive. Il faut aussi que les risques prédits soient corrects numériquement par rapport au risque observé, c’est-à-dire que les prédictions soient bien calibrées [91] . Le risque observé est calculé dans les strates de risque prédit (par exemple des déciles du risque prédit). Le risque observé (la fréquence de l’évènement) dans ces strates doit être proche de la moyenne des risques prédits pour les patients de la strate. Cette évaluation peut s’effectuer graphiquement avec en abscisse le risque prédit et en ordonnée le risque observé. Les points correspondant à chaque strate doivent être proches de la bissectrice. Des tests statistiques ont été proposés (comme le test Hosmer-Lemeshow) mais ils présentent de fortes limites.
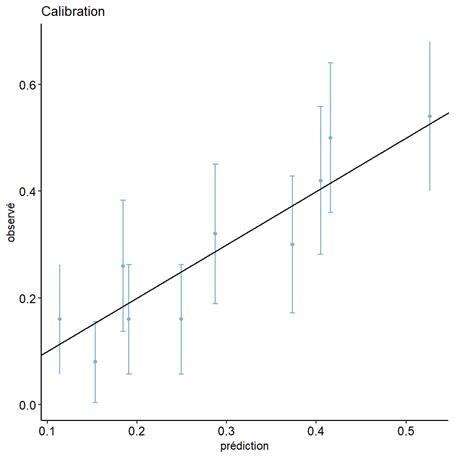
Pour être utilisé dans une approche de personnalisation des traitements en fonction du risque, la calibration est une propriété très importante. Une mauvaise calibration autour du seuil de décision peut conduire à ne pas traiter des patients pourtant à risque d’évènement ou à traiter à tort des patients à faible risque. En revanche, si l’écart de calibration survient à distance du seuil de décision (de traiter ou de ne pas traiter les patients), l’erreur numérique de la prédiction n’est pas gênante, car la décision prise à partir de cette valeur inexacte ne conduit pas à une décision erronée.
Ces aspects quantitatifs n’assurent pas à eux seuls la validité de l’outil prédictif. Il convient aussi d’écarter la présence de biais dans l’étude d’évaluation. Des outils d’évaluation de ces biais sont disponibles [92] .
