4 L’évaluation des marqueurs prédictifs
5 La personnalisation sur le risque de base
6.2.1 Modélisation de l’effet (treatment effect modelling )
6.2.2 Modèles basés sur le risque de base (Risk-based methods)
6.4 Utilisation de l’intelligence artificielle
6.4.1 Prédiction du pronostic sous traitement
6.4.2 Prédiction du bénéfice, modélisation de l’hétérogénéité des effets traitements
7 L’évaluation de l’utilité clinique par les essais de stratégie
Dans ces modèles, la probabilité de survenu de l’événement clinique servant de critère de jugement Y est modélisé en fonction du traitement et des caractéristiques de bases des sujets.
Le modèle le plus simple est appelé modèle à effet homogène
car l’effet du traitement sur Y
est considéré comme constant, homogène
pour tous les patients. Dans ce cas l’hétérogénéité des effets traitements
individuels 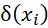 provient
de l’hétérogénéité de pronostic des patients (hétérogénéité du risque de base) du
fait que cet effet est défini en termes de différence.
provient
de l’hétérogénéité de pronostic des patients (hétérogénéité du risque de base) du
fait que cet effet est défini en termes de différence.
Pour un patient de caractéristiques xi, l’effet traitement individualisé est défini par :
*** m:r *** 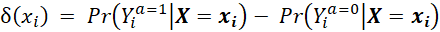
Où 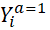 et
et 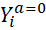 désigne
la valeur potentielle du critère de jugement Y
(potential
outcome ) du patient avec le traitement (a=1
) et sans le
traitement (a=0
) note n° 22 .
désigne
la valeur potentielle du critère de jugement Y
(potential
outcome ) du patient avec le traitement (a=1
) et sans le
traitement (a=0
) note n° 22 .
En reprenant les notations de la référence [98] , pour un sujet i , recevant le traitement a i (1 pour le traitement étudié et 0 pour le traitement contrôle) et de caractéristiques x i (qui est un vecteur de toutes les caractéristiques individuelles retenues pour la modélisation), la probabilité de l’évènement est représentée par :
*** m:r *** 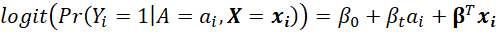
Où 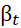 représente
l’effet du traitement et *** m:r ***
représente
l’effet du traitement et *** m:r *** 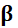 le
vecteur des coefficients rattachés aux facteurs pronostiques (et
le
vecteur des coefficients rattachés aux facteurs pronostiques (et 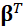 sa
transposée).
sa
transposée).
L’effet traitement individuel est estimé à partir des coefficients du modèle par
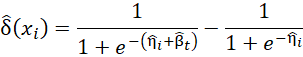
Ou 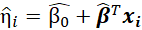 et
représente la partie pronostique du modèle.
et
représente la partie pronostique du modèle.
L’autre catégorie de modèle comporte des termes d’interaction traitement covariable permettant de modéliser des modificateurs d’effet (comme les marqueurs prédictifs) :
*** m:r *** 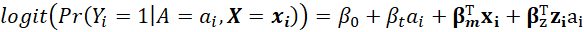
Ou z i représente le vecteur des covariables d’interaction avec le traitement (qui est un sous ensemble de x i ).
L’effet traitement individuel est estimé à partir des coefficients du modèle par
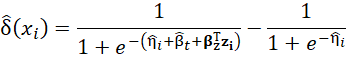
Le modèle intègre les facteurs modificateurs de l’effet (TEM) sous la forme de termes d’interaction. Cette modélisation des interactions présente de nombreuses limites (similaires à celles des analyses en sous-groupes traditionnelles) et augmente la complexité des modèles. Un risque de surdétermination (overfitting) est possible et des techniques de régularisation sont couramment utilisées pour réduire l’optimisme de ces modèles.
L’estimation de ces modèles peut s’effectuer à l’aide de nombreuses méthodes traditionnelles ou de machine learning [108] . Les techniques de machine learning (intelligence artificielle) présentent les mêmes limites que les approches statistiques habituelles et leur usage ne garantit pas d’obtenir automatiquement un modèle fiable.
La fiabilité des estimations proposées, quelle que soit la méthode utilisée, doit être démontrée par des études de validation externe satisfaisantes. Ensuite une démonstration de l’utilité médicale de ces outils, dépendant de leurs performances propres et du bien fondés des décisions thérapeutiques qu’ils engendrent, doit être apportée par des essais randomisés de stratégie (cf. section 6.5).
[22] La théorie de l’inférence causale permet de démontrer que sous l’hypothèse d’échangeabilité et de consistency, ces valeurs potentielles peuvent être estimées par les valeurs observées, par exemple, dans un essais randomisés analysés en ITT pour assurer l’hypothèses d’échangeabilité.
