4 L’évaluation des marqueurs prédictifs
5 La personnalisation sur le risque de base
6.2.1 Modélisation de l’effet (treatment effect modelling )
6.2.2 Modèles basés sur le risque de base (Risk-based methods)
6.4 Utilisation de l’intelligence artificielle
6.4.1 Prédiction du pronostic sous traitement
6.4.2 Prédiction du bénéfice, modélisation de l’hétérogénéité des effets traitements
7 L’évaluation de l’utilité clinique par les essais de stratégie
Les techniques dites d’intelligence artificielle, comme le machine learning, sont utilisées pour construire des outils prédictifs de « l’efficacité des traitements » [101 , 117] . La plupart de ces outils sont simplement prédictifs du pronostic sous traitement. Ces techniques permettent de produire un outil informatique (souvent appelé à tort algorithme) qui à partir des caractéristiques du patient (cliniques, biologiques, génétiques et/ou d’imageries) prédisent la survenue ou non d’un évènement assimilé à la non-réponse/réponse au traitement.
Trebeschi et al. proposent un outil d’IA de prédiction de la réponse aux immunothérapies dans le cancer du poumon non à petites cellules à partir des images du scanner [118] .
Ces outils ont les limites évoquées précédemment des approches de pronostic sous traitement et ne prédisent donc pas l’efficacité des traitements.
Le fait qu’il s’agisse de techniques d’intelligence artificielle ne lève en rien ces limites. Les approches de machine learning sont en effet très proches de l’approche classique de modélisation statistique et prédiction à partir du modèle [119] . Elles ont les mêmes limites comme l’indisponibilité dans le jeu de données d’apprentissage des réels prédicteurs de l’outcome, imprédictibilité intrinsèque partielle de l’outcome (phénomène aléatoire san réel prédicteur), etc. Ainsi rien ne permet d’espérer que ces approches fassent des miracles dans cette situation et puissent appréhender la réelle valeur prédictive d’un marqueur à travers une simple mesure de sa valeur pronostique sous traitement.
Hakeem et al. [120] rapporte la construction d’un outil de prédiction de la réponse au traitement dans l’épilepsie nouvellement diagnostiquée. La réponse est définie par l’absence de crise durant l’année suivant l’instauration du premier traitement. Un réseau neural de type « transformer » a été entrainé à partir des données d’une cohorte de patients traités par un anticonvulsivant. Le modèle a ensuite été testé sur 4 autres cohortes pour sa validation externe note n° 23 .
Les performances du modèle s’avèrent assez modestes avec une aire sous la courbe pour la partie validation (test) à 0.65. La conclusion du papier est qu’une amélioration de la prédiction est nécessaire.
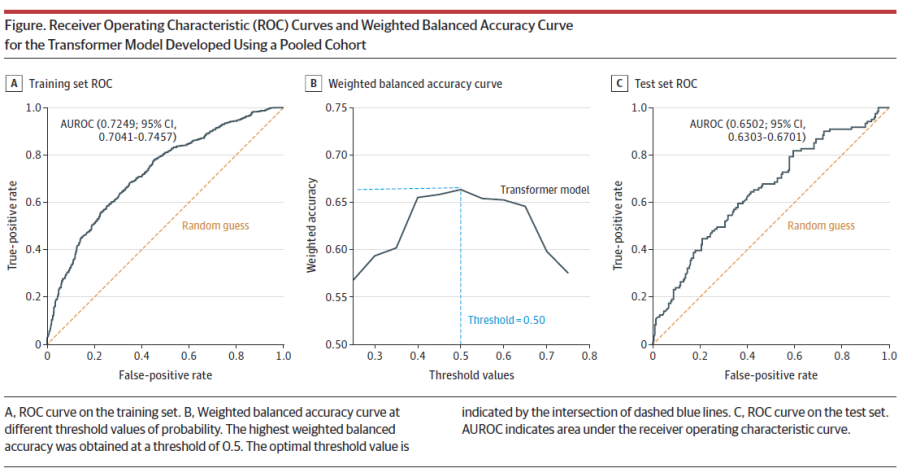
Tous les patients des cohortes utilisées étant des patients traités, ce travail ne prédit donc pas l’effet des traitements, mais bien l’évolution sous traitement (pronostique sous traitement). Aucun contrôle n’a été utilisé afin de vérifier que l’outil ne prédisait pas simplement le niveau de sévérité de l’épilepsie. Comme discuté en section 4.1 il y a une impossibilité dans cette approche « treatment only » de distinguer les facteurs de réponse des facteurs pronostiques.
On peut aussi remarquer que le modèle ne permet pas de prédire la réponse à chaque molécule, car la réponse modélisée est indépendante du traitement utilisé. Cet outil dans cette forme ne permettrait donc pas de faire de la personnalisation de traitement.
[23] Mais le papier laisse suggérer qu’il y a un extra tuning (complément d’apprentissage) lors de cette étape, ce qui transforme cette étape en étape d’apprentissage et non plus en étape de validation externe.
